linux学习记录:记一次predixy容器化性能优化
一、背景
最近在做predixy的多线程云原生适配,在一套新的虚拟机环境上做性能压测的时候,发现CPU一直存在跑不满的情况。
本文简单记录下这个问题的排查流程和结果。
压测时的predixy pod中观察一下top信息如下:
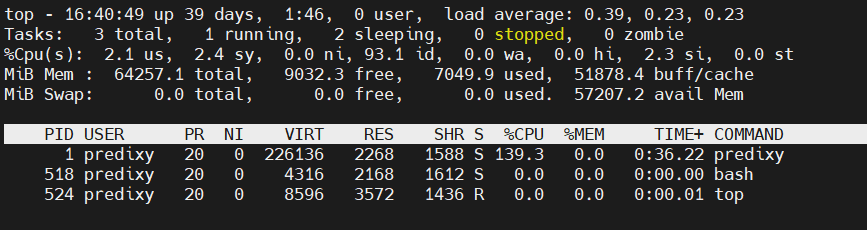
其中predixy pod的cpu limit设置为两核,predixy配置为2线程,但CPU只能跑到130%左右。
二、排查思路
思路一: 发压端问题
根据此思路,不断调整发压端的线程、包大小等数据,但CPU占比变化不大,仍无法跑满。
故非发压端问题,此思路paas.
思路二:代理本身问题
根据此思路,将predixy在本地物理机里运行压测,当predixy配置为2线程时,CPU可以跑满到200%
故非代理本身问题,此思路paas.
思路三:环境网络问题
根据此思路,调整发压端和predixy之间通信的网络。
此前压测时,predixy地址为Nodeport svc地址。
首先调整为pod网络,CPU仍无法跑满,和使用Nodeport svc时整体相差不大。
随后调整为hostnetwork网络,此时CPU几乎可以跑满,故考虑是网络上的问题,开始寻求容器平台大佬介入帮助。
三、排查结果
根据跟容器大佬们的沟通,最终定位出了问题,结果如下:
首先这套K8S集群环境是虚拟机,使用calico网络,hostnetwork和calico网络方案处理数据包的链路有点区别:
对于hostnetwork,容器完全使用宿主机的网络,网络数据包直接通过物理网卡到达网路协议栈。
对于calico网络,网络数据包多了一层虚拟网卡的转发,会多过一节veth
所以predixy网络包的处理过程中,会涉及到到host端的veth的rx收包。
linux默认哪个cpu触发的rx,最终rx的软中断就会在哪个cpu上运行。这就导致I/O操作多时,软中断会很占用资源。
比如线程A当前在cpu 0上,那么最终触发host端的rx收包的软中断也会是cpu 0来触发,也会在cpu 0上来执行。linux调度器观察到这个情况后,会认为cpu 0太忙了,将进程迁移到其他cpu上,陷入死循环。
物理网卡已经开启rss,来缓解这个问题;但veth未开启。
故实际上就是这套K8s环境使用虚拟机搭建,其中涉及到veth设备,由于未做特殊处理,放大了predixy进程的软中断消耗,导致CPU跑不上去。
四、解决方案
经过向大佬们请教,得知这种情况下一般要把veth的rps打开。
原理就是把其软中断的处理绑到特定的cpu核心上,这样原来的其余的cpu核心,就可以安安稳稳干业务了。
一般这种要做好CPU预留,把这一部分的cpu专门来处理veth的rx软中断就好了
相关脚本如下:
1 | !/bin/bash |